Projekty
Dino Run
![[OBRAZEK]](projects/47.jpg)
Celem pracy było zaimplementowanie i przetestowanie działania algorytmu Double Deep Reinforcement Learning. Wprowadzenie do algorytmów RL zostało przedstawione w artykule “Reinforcement Learning - sztuka metody prób i błędów” [1], a podstawy Q-Learningu w “Q-Learning i SARSA - bez ryzyka nie ma zabawy” [2].
Głównym problemem Q-Learningu jest to, że wraz ze wzrostem skomplikowania rozwiązywanego problemu, Q tablica rozrasta się do rozmiarów uniemożliwiających jej wydajne przeszukiwanie. Dla przykładu, jeżeli naszym stanem jest pozycja gracza, a akcją kierunek ruchu, dla małej planszy 4x4 i 4 kierunków ruchu dostajemy Q tablicę o wymiarach 16x4. Jednak już dla planszy 50x50 Q tablica będzie rozmiaru 2500x4, a środowisko nie jest nawet skomplikowane.
W związku z tym stworzono nową kategorię RL: Deep Reinforcement Learning. Odpowiadający Q-Learningowi algorytm Deep Q Learning zamienia Q tablicę na głęboką sieć neuronową.
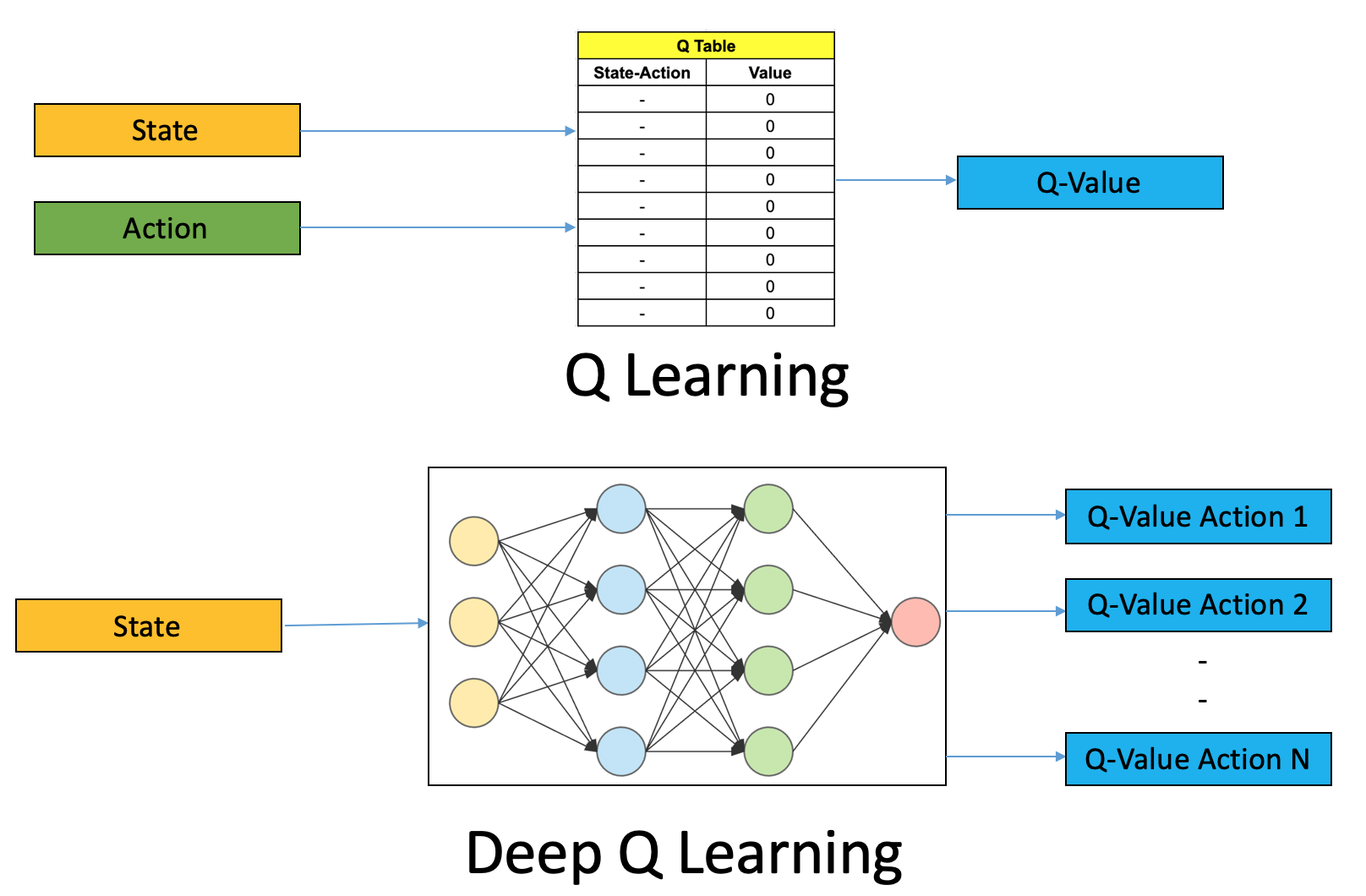
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/0ea7f4fc8f.jpg)
Rysunek 1: Porównanie algorytmów Q Learning I Deep Q Learning. [3] (https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/04/Screenshot-2019-04-16-at-5.46.01-PM.png)
Algorytm Double Deep Q Learning jest dalszym udoskonaleniem powyższego rozwiązania. Eliminuje on problem wybierania zawsze najwyższej wartości zwracanej przez sieć poprzez dodanie drugiej sieci neuronowej, “zamrażanej” na pewne okresy. Przez to zwracane przez nią wartości nieznacznie różnią się od głównej sieci. Pozwala to na usunięcie dużej części niestabilności Deep Q Learningu.
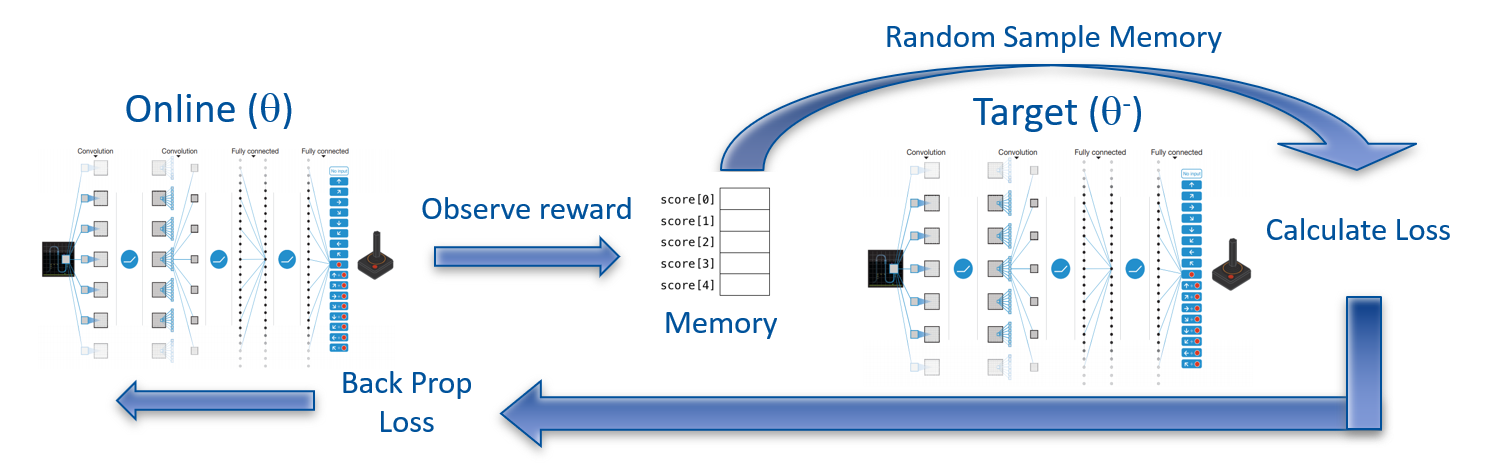
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/d2fdc0e4ba.jpg)
Rysunek 2: Pętla Double Deep Q Learning. [4] (https://www.jbocinsky.com/assets/images/DoubleQLearningProcess.png)
Dla przetestowania zaimplementowanego algorytmu stworzyłam kopię popularnej gry Dino Run.
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/6d2c8658c4.jpg)
Rysunek 3: Przykładowa klatka z gry.
Celem agenta było uzyskanie jak największej liczby punktów, których limit ustawiłam na 50. Każda klatka gry była analizowana pod względem występujących obiektów.
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/cd4c8e192e.jpg)
Rysunek 4: Przedstawienie obiektów gry: gracza, kaktusa oraz pterodaktyla.
Następnie obiekty te były przetwarzane na odpowiednie liczbowe znaczniki.
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/86202c197b.jpg)
Rysunek 5: Pełna tablica klatki z gry z mapowaniem liczbowym obiektów.
Tablica ta była następnie przycinana, ponieważ jej wyższa część pozostaje niezmienna w trakcie rozgrywki.
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/a5be256c3d.jpg)
Rysunek 6: Tablica przycięta o zbędne pola.
Wynik tych działań był ostatecznie przekazywany do sieci neuronowej jako jedno-wymiarowa tablica znaczników.
Następna część projektu opierała się głównie na odpowiednim dobraniu parametrów sieci oraz metodyki uczenia (czasu, zmian nagród itd). Ostatecznie agent był w stanie nauczyć się przechodzenia gry ze znacznie lepszym wynikiem niż człowiek grający przy tych samych warunkach.
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/9e244546f5.jpg)
Rysunek 7: Przykładowe przejście gry przez agenta.
Projekt został całkowicie zrealizowany Pythonie, do gry użyto biblioteki Pygame, a algorytmy uczenia ze wzmocnieniem wykorzystują bibliotekę Keras.
Głównym problemem Q-Learningu jest to, że wraz ze wzrostem skomplikowania rozwiązywanego problemu, Q tablica rozrasta się do rozmiarów uniemożliwiających jej wydajne przeszukiwanie. Dla przykładu, jeżeli naszym stanem jest pozycja gracza, a akcją kierunek ruchu, dla małej planszy 4x4 i 4 kierunków ruchu dostajemy Q tablicę o wymiarach 16x4. Jednak już dla planszy 50x50 Q tablica będzie rozmiaru 2500x4, a środowisko nie jest nawet skomplikowane.
W związku z tym stworzono nową kategorię RL: Deep Reinforcement Learning. Odpowiadający Q-Learningowi algorytm Deep Q Learning zamienia Q tablicę na głęboką sieć neuronową.
{kind=link}
Algorytm Double Deep Q Learning jest dalszym udoskonaleniem powyższego rozwiązania. Eliminuje on problem wybierania zawsze najwyższej wartości zwracanej przez sieć poprzez dodanie drugiej sieci neuronowej, “zamrażanej” na pewne okresy. Przez to zwracane przez nią wartości nieznacznie różnią się od głównej sieci. Pozwala to na usunięcie dużej części niestabilności Deep Q Learningu.
{kind=link}
Dla przetestowania zaimplementowanego algorytmu stworzyłam kopię popularnej gry Dino Run.
Celem agenta było uzyskanie jak największej liczby punktów, których limit ustawiłam na 50. Każda klatka gry była analizowana pod względem występujących obiektów.
Następnie obiekty te były przetwarzane na odpowiednie liczbowe znaczniki.
| Nothing | Player | Cactus | Pterodactyl |
| 0 | 1 | 2 | 3 |
Tablica ta była następnie przycinana, ponieważ jej wyższa część pozostaje niezmienna w trakcie rozgrywki.
Wynik tych działań był ostatecznie przekazywany do sieci neuronowej jako jedno-wymiarowa tablica znaczników.
Następna część projektu opierała się głównie na odpowiednim dobraniu parametrów sieci oraz metodyki uczenia (czasu, zmian nagród itd). Ostatecznie agent był w stanie nauczyć się przechodzenia gry ze znacznie lepszym wynikiem niż człowiek grający przy tych samych warunkach.
Projekt został całkowicie zrealizowany Pythonie, do gry użyto biblioteki Pygame, a algorytmy uczenia ze wzmocnieniem wykorzystują bibliotekę Keras.
[1] http://main.p.lodz.pl/news.php?id=105
[2] http://main.p.lodz.pl/news.php?id=124
[3] https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/04/Screenshot-2019-04-16-at-5.46.01-PM.png
[4] https://www.jbocinsky.com/assets/images/DoubleQLearningProcess.png
Data zakończenia: 10.2.2021
Autorzy

Alicja Krautsztrung