Aktualności
Jak komputer rozumie nasz kod źródłowy? – Lekser i parser (część 2)
Dodano: 2020-11-03
Niniejszy artykuł jest drugą częścią z serii. Aby w pełni go zrozumieć, koniecznie przeczytaj część pierwszą [LINK].
Zadaniem parsera jest wzięcie wygenerowanych wcześniej przez lexer tokenów i przekształcenie ich w Abstract Syntaxt Tree (z ang. drzewo składniowe) lub krócej - po prostu AST. Czym jest AST? Z nazwy można wywnioskować, że ma strukturę drzewa, choć nie musi – ważniejsze jest jego główne założenie. Struktura AST powinna przedstawiać działanie programu w sposób abstrakcyjny, czyli przedstawiający jedynie jego sposób działania. Pamiętasz przykład z poprzedniego artykułu „Ala ma kota”? Można by powiedzieć, że lexer dzieli zbiór znaków na słowa, a parser analizuje te słowa próbując złożyć je w jedno zdanie z pewnym znaczeniem. Wygląda to mniej więcej tak:
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/2f69f72486.jpg)
Proces przekształcania tokenów na AST nazywamy analizą składniową (to właśnie podczas tego procesu otrzymujemy te wszystkie „syntax errory”).
Każdy node (z ang. węzeł) w wygenerowanym AST może być jednym z trzech typów:
• declaration (z ang. deklaracja) – jest to kawałek kodu, który np. wprowadza nową zmienną do programu. Przykładowa deklaracja może wyglądać tak:![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/1b3f2c383d.jpg)
• expression (z ang. wyrażenie) – fragment programu, który produkuje jakąś wartość (np. obliczenie matematyczne czy wywołanie funkcji). Dla przykładu:![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/6daf315fd6.jpg)
• statement (z ang. instrukcja) – każdy wykonywalny kawałek programu (np. while, return, for). Przykład:
Chwilka, co? Przecież to jest deklaracja…
I tutaj wyłania się oblicze skomplikowania procesu analizy semantyki języka, ponieważ w większości języków programowania:
• instrukcja może być wyrażeniem,
• instrukcja może zawierać wyrażenie ,
• instrukcja może składać się z innych instrukcji,
• deklaracja może zawierać wyrażenie,
• wyrażenie prawie zawsze składa się z wielu innych wyrażeń.
Język powinien mieć dobrze zdefiniowaną gramatykę. No więc zdefiniujmy przykładową gramatykę (będzie bardzo zbliżona do gramatyki języka C i podobnych). Odpowiedzmy sobie najpierw na pytanie – z czego składa się program?
W naszej definicji program będzie składał się z wielu instrukcji.
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/7f3b0f6cc7.jpg)
Powyżej przedstawiony jest przykładowy program, który jest zbiorem trzech instrukcji. Możemy zdefiniować ogólną strukturę programu jako zasadę gramatyczną w ten sposób:
Wyróżnijmy parę przykładowych instrukcji:
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/4aeea3f703.jpg)
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/608b63f9f8.jpg)
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/f4ecc6b25f.jpg)
Wyróżnijmy jeszcze jeden typ:
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/7b04c554a4.jpg)
Niestety, to nie koniec. Został jeszcze jeden niewyjaśniony element tej układanki – wyrażenia. Do tego są one tak samo, jeśli nie bardziej, skomplikowane od całej reszty.
Czym może być wyrażenie? Cóż…
• literał to wyrażenie,
• wyrażenie objęte nawiasami kwadratowymi, które jest poprzedzone innym wyrażeniem, również jest wyrażeniem,
• wyrażenie, po którym występuje wyrażenie w nawiasach, też jest rodzajem wyrażenia,
• …dwa wyrażenia oddzielone operatorem binarnym formują wyrażenie,
• wyrażenie posiadające operator unarny po dowolnej ze stron to [drum roll] też wyrażenie!
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/ed8322c04f.jpg)
Na obrazku mamy dwa wyrażenia: jednym jest literał liczbowy 123, a drugim literał łańcuchowy „lorem”. Tyle. Przy okazji wiemy już, że te dwie linijki są instrukcjami, ponieważ pasują do pewnej zasady, którą wcześniej zdefiniowaliśmy:
Przejdźmy dalej:
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/a890177273.jpg)
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/f61f5efe1c.jpg)
Dokładne omówienie każdego typu wyrażenia zajęłoby zbyt dużo czasu, także skupię się na wyrażeniach matematycznych, ponieważ wprowadzają one kolejny problem do rozwiązania – pierwszeństwo operatorów. W językach programowania problem ten nie jest ekskluzywny do wyrażeń matematycznych, ponieważ każde wyrażenie, w którym pojawia się dowolny operator, musi wziąć pod uwagę jego pierwszeństwo i pierwszeństwo innych operatorów w danym wyrażeniu.
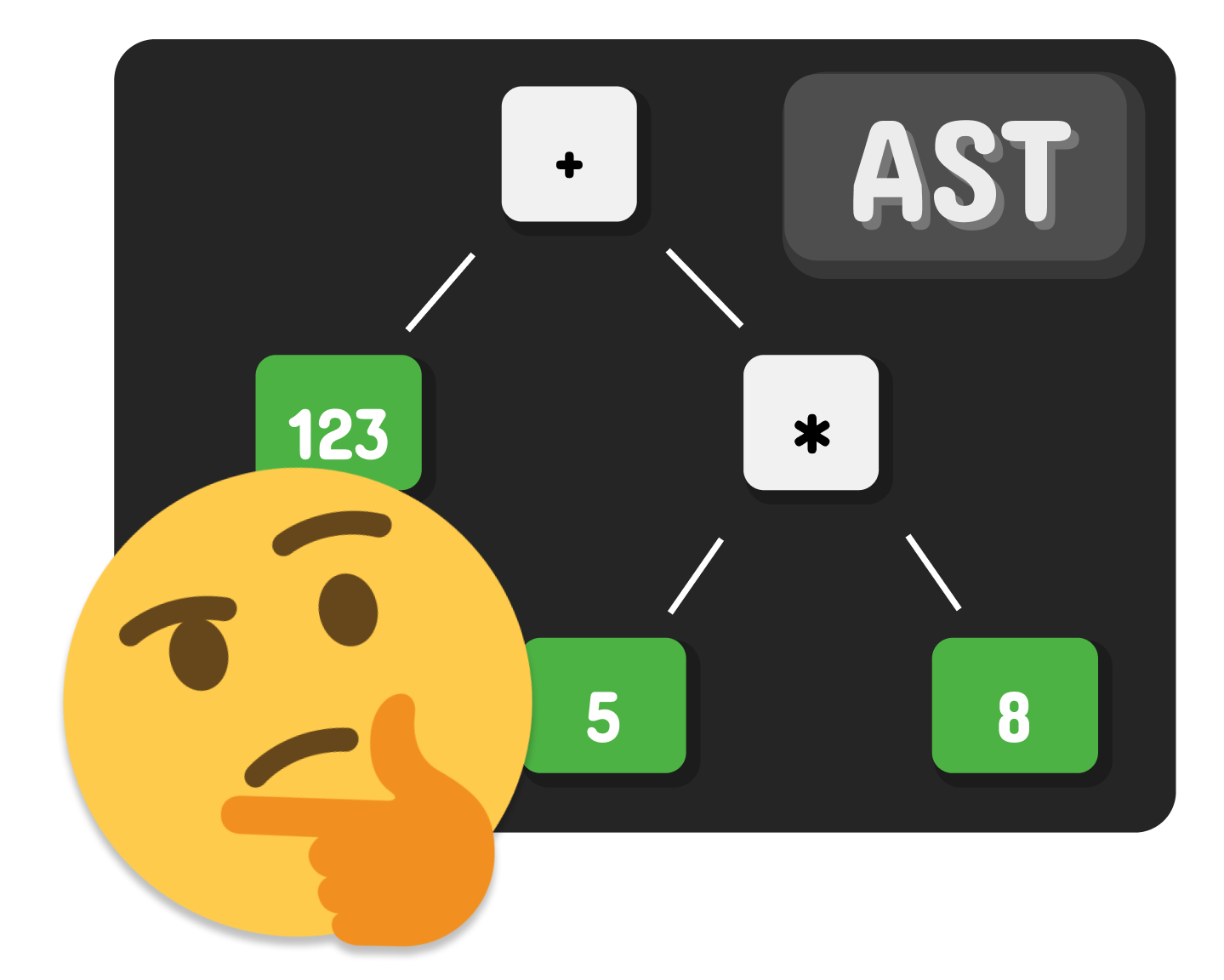
Widząc działanie 123 + 5 * 8 wszyscy dobrze wiemy, że mnożenie ma pierwszeństwo nad dodawaniem. Podobne zasady obowiązuje większość języków programowania. Chcąc uniknąć ciągłego grupowania wyrażeń w nawiasy polegamy na znanych nam zasadach pierwszeństwa operatorów. Dobrze działający parser powinien również radzić sobie z tym problemem i potrafić przekształcać skomplikowane wyrażenia do postaci, która umożliwia ich ewaluację w odpowiedni sposób. W skrócie – AST wyrażeń generowane przez parser powinno być tak skonstruowane, aby nie było niejasności, w jaki sposób ma zostać obliczone dane wyrażenie.
Tak więc wyrażenie:
powinno zostać przekształcone do takiej postaci:
![[OBRAZEK]](http://main.p.lodz.pl/art_img/images/cd20b9bfc1.jpg)
Jak to osiągnąć? Z pomocą przychodzi tzw. shunting-yard algorithm. Algorytm ten jest używany do parsowania wyrażeń matematycznych, ale jego uniwersalność pozwala na parsowanie dowolnych wyrażeń w językach programowania. W zależności od implementacji wynikiem działania takiego algorytmu jest RPN (odwrotna notacja polska) lub AST.
Ale wcześniej parę słów o operatorach.
Aby algorytm dobrze działał musimy zdefiniować dwie własności każdego operatora:
2. Asocjatywność – wyróżniamy asocjatywność „od lewej do prawej” i „od prawej do lewej”. W pierwszym wypadku lewy operand powinien być sprowadzony do najprostszej postaci, a w drugim odwrotnie. Dla przykładu: dodawanie jest operacją wykonywaną od lewej do prawej, a wszelkie operatory przypisania („=”, „+=” itp.) są wykonywane od prawej do lewej – zanim przypiszemy coś do zmiennej, musi być znana dokładna jej wartość.
• Dla każdego tokenu:
o jeśli aktualny token nie jest operatorem:
> wrzuć go na stos,
o w przeciwnym wypadku:
> dopóki są tokeny na stosie i token na górze stosu jest operatorem, i operator na górze stosu ma pierwszeństwo nad aktualnym tokenem lub mają takie same pierwszeństwo, i aktualny token ma lewą asocjację:
- usuń token z góry stosu i wrzuć go do kolejki,
> wrzuć aktualny token na stos.
• Dopóki są tokeny na stosie:
o usuń token z góry stosu i wrzuć go do kolejki.
I to będzie na tyle jeśli chodzi o parsowanie. Tak wyglądają dwa pierwsze etapy, które przechodzi każdy napisany przez nas program.
Co się dzieje dalej? To już zależy. Języki kompilowane przechodzą przez proces optymalizacji oraz analizy w celu weryfikacji poprawności naszego kodu, AST jest potem przetwarzane do kodu pośredniego (IR), następnie do kodu maszynowego, a na koniec całość jest łączona ze sobą (w przypadku wielu plików). Jeśli chodzi o języki interpretowane, wykonywanie kodu zazwyczaj zaczyna się od razu po skonstruowaniu AST. Brzmi jak temat na kolejny artykuł? Może kiedyś.